Transformer 是一种基于自注意力机制的深度学习模型,最初应用于自然语言处理领域,现已扩展到图像、音频等多个领域。与传统的循环神经网络 (RNN) 不同,Transformer 不依赖于顺序数据处理,能够并行计算,从而显著提高效率。
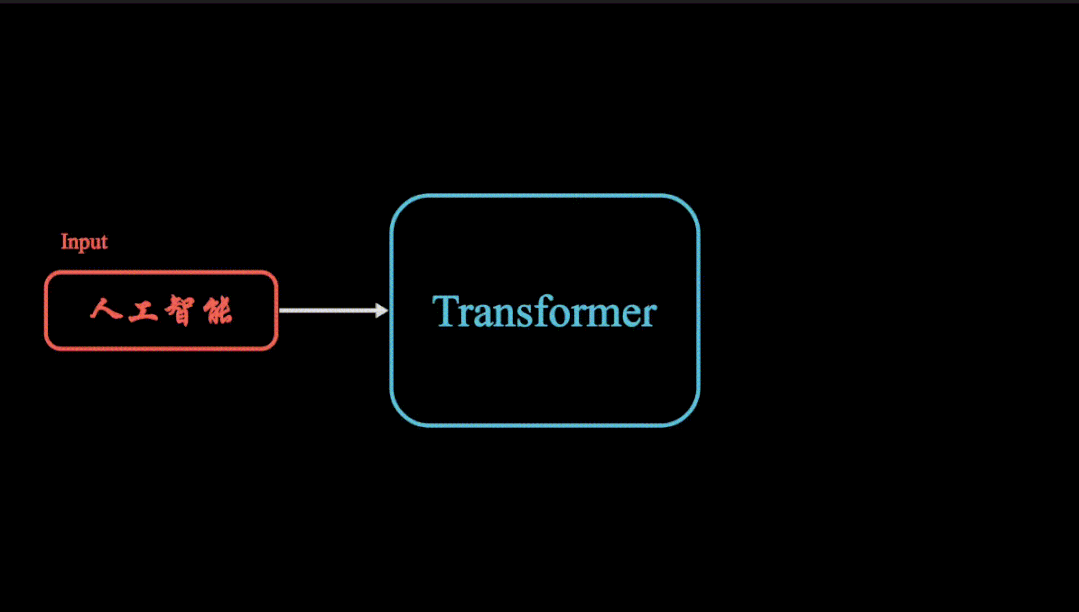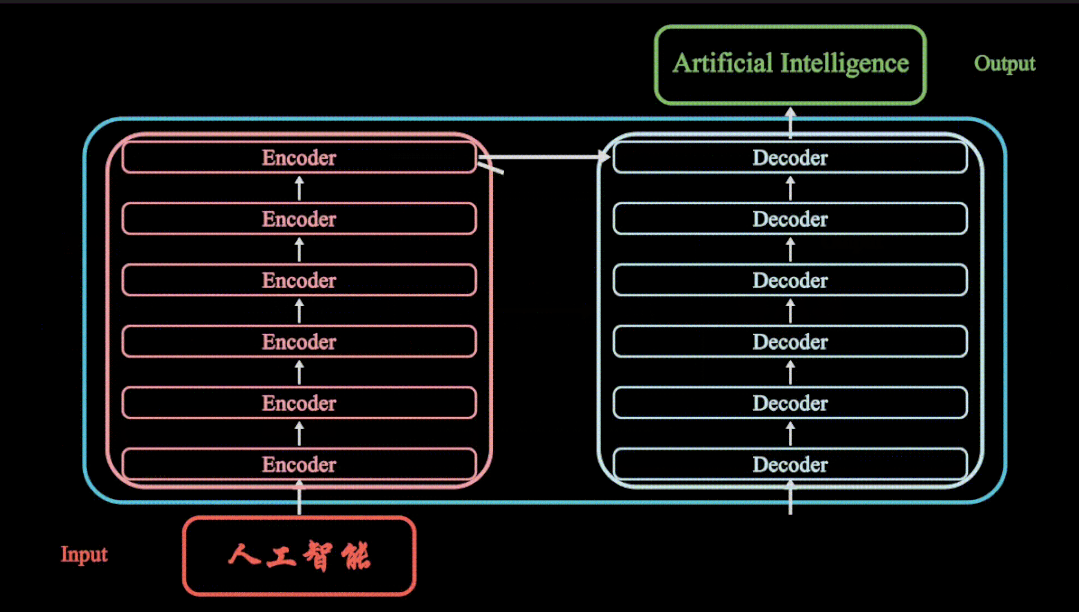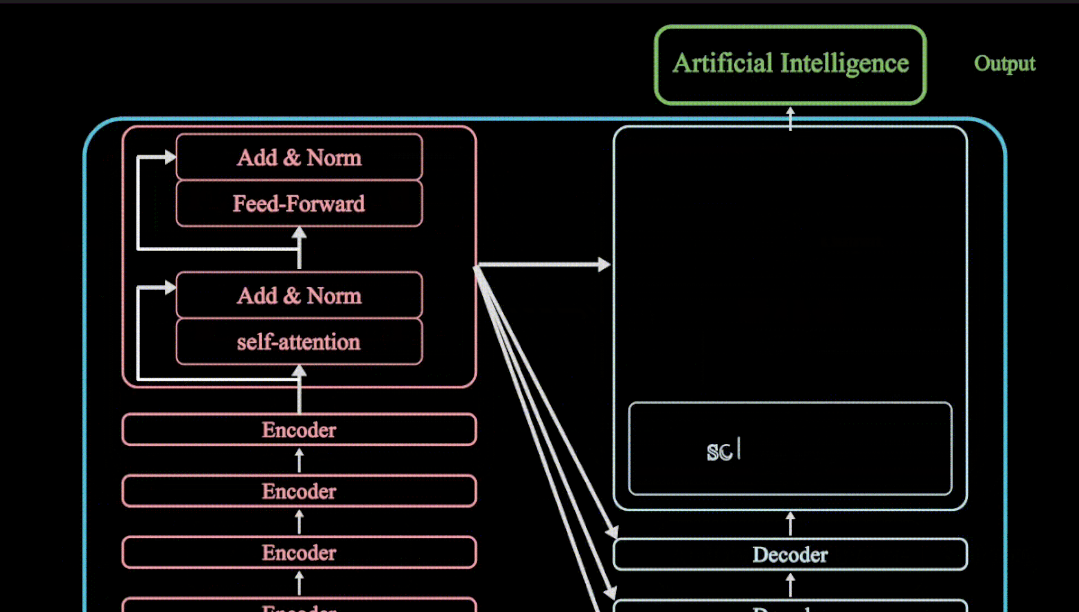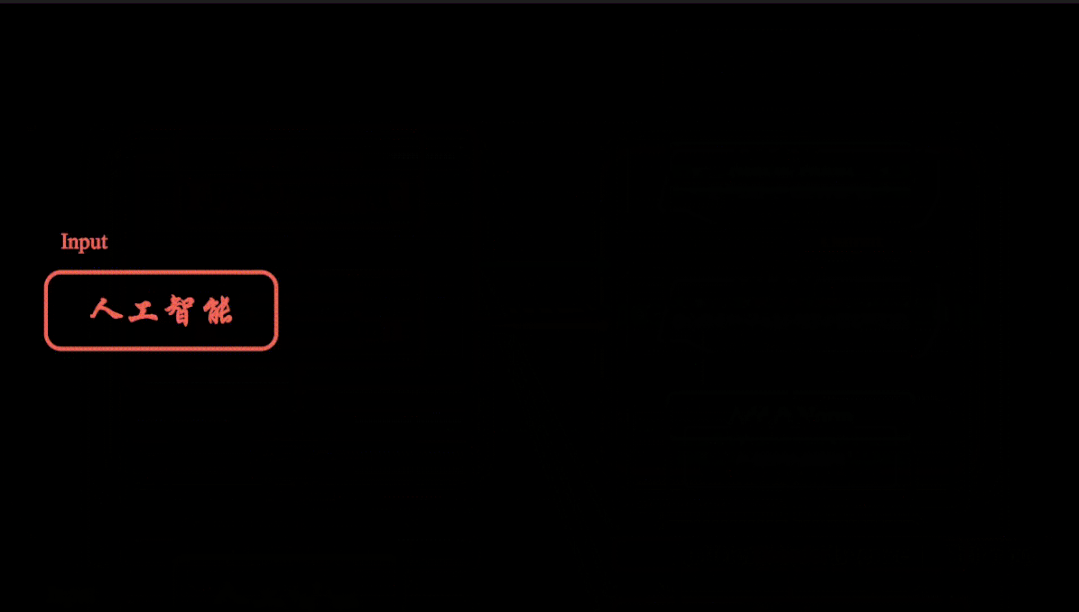
Transformer 结构
Transformer 模型主要由编码器和解码器两部分组成,每个部分都包含多个相同的层堆叠而成。
- 编码器: 负责将输入序列转换为高维特征表示。
- 解码器: 负责根据编码器的输出生成目标序列。
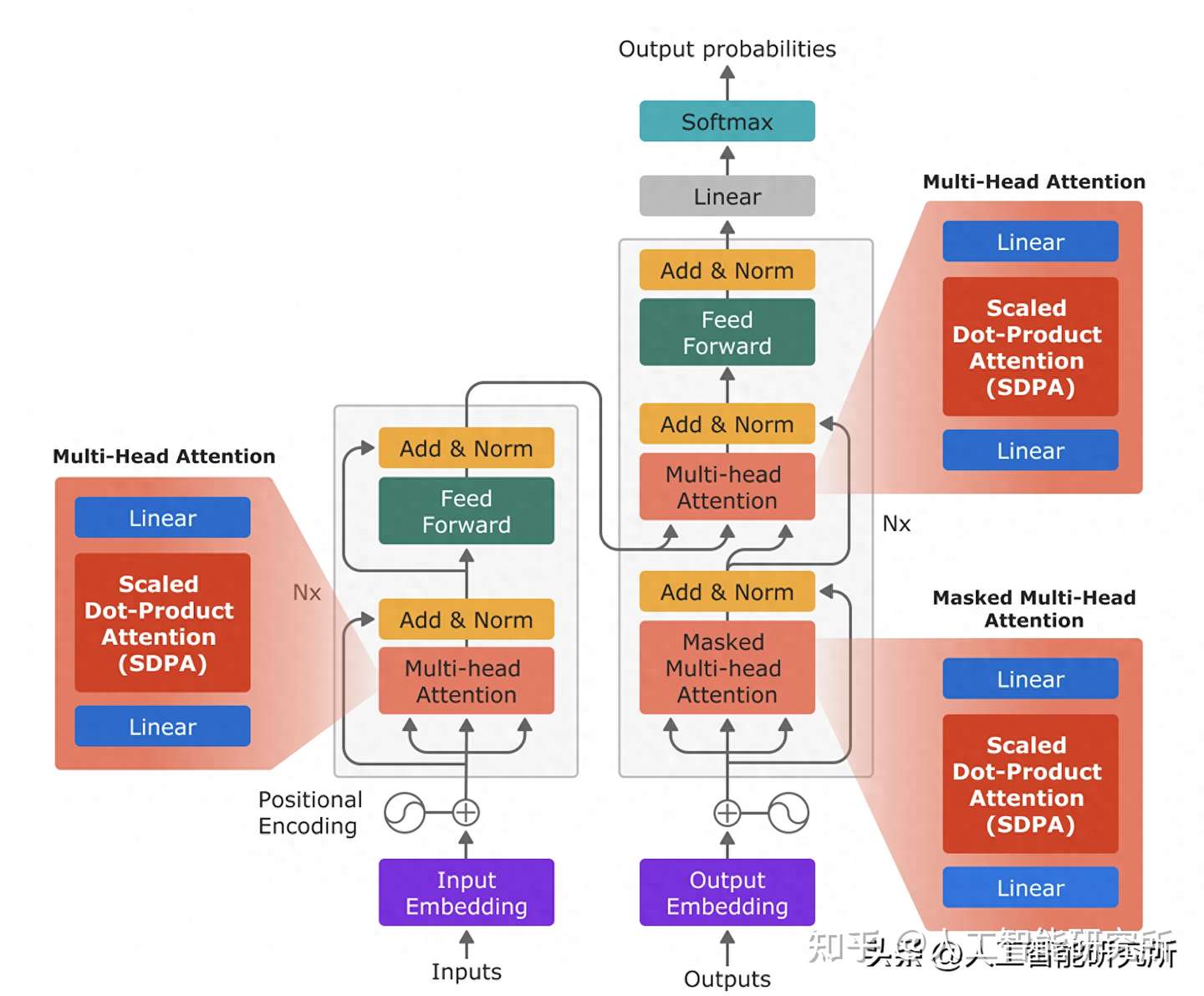
transformer模型框架
每个 Transformer 层包含以下核心组件:
- 自注意力机制 (Self-attention): 自注意力机制允许模型关注输入序列中的所有 token,并学习它们之间的依赖关系。它通过计算每个 token 与其他 token 的相似度得分,生成一个注意力矩阵,用于加权平均所有 token 的特征表示,从而获得每个 token 的上下文表示。
- 前馈神经网络 (Feed-forward Neural Network): 对自注意力机制的输出进行非线性变换,进一步提取特征。
- 残差连接 (Residual Connection) 和层归一化 (Layer Normalization): 用于缓解梯度消失问题,加速模型训练。
注意力长度带来的计算复杂度问题
自注意力机制的计算复杂度为 O(n^2),其中 n 是输入序列的长度。这意味着随着序列长度的增加,计算量和内存占用会急剧增长,导致出现各种问题:
- 计算资源限制: 处理长序列需要大量的计算资源,限制了模型的应用场景。
- 内存占用过高: 长序列的注意力矩阵尺寸过大,容易超出内存容量。
- 训练效率低下: 计算量和内存占用的增加会导致模型训练速度变慢。
为了解决注意力长度带来的计算复杂度问题,研究者提出了多种改进方案,例如:
- 滑动窗口注意力: 只关注局部上下文信息,将注意力范围限制在一个固定大小的窗口内。
- 稀疏注意力: 只计算部分 token 之间的注意力得分,降低注意力矩阵的密度。
- 线性注意力: 使用核函数近似计算注意力得分,将计算复杂度降低到 O(n log n)。
- 压缩内存: 使用压缩内存存储和检索长期上下文信息,避免注意力矩阵的过度增长。
Infini-Transformer模型—无限注意力机制长度
论文介绍了一种高效的方法,可以将基于 Transformer 的大型语言模型 (LLM) 扩展到无限长的输入,同时保持有限的内存和计算量。论文提出的方法中的关键组件是一种称为 Infini-attention 的新型注意力机制。Infini-attention 将压缩内存整合到 vanilla 注意力机制中,并在单个 Transformer 块中构建了掩码局部注意力和长期线性注意力机制。在长上下文语言建模基准测试、100 万序列长度的密钥上下文块检索和 50 万长度的书籍摘要任务中,使用 10 亿和 80 亿参数的 LLM 证明了此方法的有效性。此方法引入了最小的有限内存参数,并为 LLM 实现了快速的流式推理。

Infini-Transformer模型框架
上图展示了 Infini-attention 的结构,它结合了压缩内存、掩码局部注意力和长期线性注意力机制,以实现对无限长上下文的有效处理。
数据传递过程
- 输入: Infini-attention 接收当前输入分段的 token 嵌入 Xs 作为输入。
- 局部注意力: Xs 首先经过标准的缩放点积注意力层,计算局部上下文表示 Adot。这部分注意力只关注当前分段内的 token,类似于传统的 Transformer 注意力机制,使用掩码机制保证只关注到当前时间步及之前的token。
- 查询、键、值: 与局部注意力并行,Xs 还用于生成查询向量 Qs、键向量 Ks 和值向量 Vs。
- 压缩内存检索: 查询向量 Qs 用于从压缩内存 Ms-1 中检索相关信息,生成长期上下文表示 Amem。
- 内存更新: 压缩内存 Ms-1 使用当前分段的键 Ks 和值 Vs 进行更新,生成新的压缩内存 Ms,用于下一个分段的处理。
- 上下文聚合: 局部上下文表示 Adot 和长期上下文表示 Amem 通过一个可学习的门控机制进行聚合,生成最终的上下文表示 A。
- 输出: 最终的上下文表示 A 经过线性投影生成 Infini-attention 的输出 Os。
计算过程
局部注意力: 使用标准的缩放点积注意力机制计算,公式如下:
Adot = softmax(Qs Ks^T / sqrt(d_model)) Vs
其中,d_model 是模型的维度。
压缩内存检索: 使用线性注意力机制计算,公式如下:
Amem = σ(Qs) Ms-1 / (σ(Qs) zs-1)
其中,σ 是非线性激活函数(例如 ELU+1),zs-1 是用于数值稳定的归一化项,Ms-1 是上一分段的压缩内存。
内存更新: 使用线性或线性+delta规则进行更新,公式如下:
线性:
Ms = Ms-1 + σ(Ks)^T Vs zs = zs-1 + ∑_{t=1}^{N} σ(Ks_t)
线性+delta:
Ms = Ms-1 + σ(Ks)^T (Vs - σ(Ks) Ms-1 / (σ(Ks) zs-1)) zs = zs-1 + ∑_{t=1}^{N} σ(Ks_t)
上下文聚合: 使用可学习的门控机制进行聚合,公式如下:
A = sigmoid(β) * Amem + (1 - sigmoid(β)) * Adot
其中,β 是一个可学习的标量参数。
Infini-Transformer模型性能对比

Infini-Transformer 模型和 Transformer-XL 模型在处理多段文本时的区别
上图对比了 Infini-Transformer 模型和 Transformer-XL 模型在处理多段文本时的区别,重点突出了 Infini-Transformer 模型如何利用压缩内存来保留全部的上下文信息。
上半部分 (Infini-Transformer): 展示了 Infini-Transformer 处理三段文本的过程。
- 每一段文本进入 Transformer block 进行处理,同时更新压缩内存。
- 压缩内存随着处理的文本段数增加而不断积累信息。
- 模型能够访问所有先前段落的上下文信息,实现无限长的上下文窗口。
下半部分 (Transformer-XL): 展示了 Transformer-XL 处理三段文本的过程。
- 每一段文本进入 Transformer block 进行处理,并缓存最后一个段落的 KV 状态。
- 模型只能访问最后一个段落的上下文信息,上下文窗口受限于缓存大小。
- 旧的上下文信息会被丢弃,导致信息丢失。
Infini-Transformer 能够利用压缩内存保留全部的上下文历史信息,而 Transformer-XL 只能保留最后一个段落的上下文信息;Infini-Transformer 实现了无限长的有效上下文窗口,而 Transformer-XL 的上下文窗口受限于缓存大小;Infini-Transformer 避免了 Transformer-XL 中旧上下文信息丢失的问题。与其他模型相比,其内存大大有所降低,且可以处理很大很长的数据文本。

模型内存占用对比
表中参数含义: N: 输入分段长度 S: 分段数量 l: 层数 H: 注意力头数量 c: Compressive Transformer 的记忆大小 r: 压缩率 p: Soft-prompt 摘要向量数量 m: 摘要向量累积步数
- 记忆占用: Infini-Transformers 的记忆占用与输入序列长度无关,保持恒定。其他模型的记忆占用会随着序列长度增加而线性增长,导致内存瓶颈。
- 上下文长度: Infini-Transformers 支持无限长的上下文窗口,而其他模型的上下文窗口受限于缓存大小或 Soft-prompt 数量。
- 记忆更新: Infini-Transformers 使用增量式更新机制,不断积累长期信息,而其他模型会丢弃旧的记忆内容,导致信息丢失。
- 记忆检索: Infini-Transformers 使用高效的线性注意力机制检索长期信息,而其他模型使用计算成本更高的点积注意力或 kNN 检索。
Infini-Transformer模型试验结果
Transformer 中的注意力机制在内存占用和计算时间上都表现出二次复杂度。例如,对于一个 5000 亿参数的模型,批大小为 512,上下文长度为 2048,注意力键值 (KV) 状态的内存占用为 3TB(Pope et al., 2023)。事实上,使用标准 Transformer 架构将 LLM 扩展到更长的序列(即 100 万个 token)是具有挑战性的,而且服务越来越长的上下文模型在经济上变得成本高昂。

模型性能对比
压缩内存系统有望比注意力机制更具可扩展性和效率,适用于极长的序列。压缩内存没有使用随着输入序列长度增长的数组,而是主要维护固定数量的参数来存储和调用信息,并具有有限的存储和计算成本。对 Transformer 注意力层的这种微妙但关键的修改使得现有的 LLM 能够通过持续的预训练和微调自然地扩展到无限长的上下文。
Infini-attention 重用了标准注意力计算的所有键、值和查询状态,用于长期内存整合和检索。将注意力的旧 KV 状态存储在压缩内存中,而不是像标准注意力机制那样丢弃它们。然后,在处理后续序列时使用注意力查询状态从内存中检索值。为了计算最终的上下文输出,Infini-attention 聚合了长期内存检索的值和局部注意力上下文。

文本长度与摘要性能对比
实验表明,此方法在长上下文语言建模基准测试中优于基线模型,同时在内存大小方面具有 114 倍的压缩率。一个 10 亿参数的 LLM 自然地扩展到 100 万序列长度,并在注入 Infini-attention 后解决了密钥检索任务。最后,在持续预训练和任务微调后,具有 Infini-attention 的 80 亿参数的模型在 50 万长度的书籍摘要任务上达到了新的 SOTA 结果
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:启示AI科技
微信中复制如下链接,打开,免费使用chatgpt
https://wx2.expostar.cn/qz/pages/manor/index?id=1137&share_from_id=79482&sid=24
动画详解transformer 在线教程